Abstract
Recent text-to-3D generation methods achieve impressive 3D content creation capacity thanks to the advances in image diffusion models and optimizing strategies. However, current methods struggle to generate correct 3D content for a complex prompt in semantics, i.e., a prompt describing multiple interacted objects binding with different attributes. In this work, we propose a general framework named Progressive3D, which decomposes the entire generation into a series of locally progressive editing steps to create precise 3D content for complex prompts, and we constrain the content change to only occur in regions determined by user-defined region prompts in each editing step. Furthermore, we propose an overlapped semantic component suppression technique to encourage the optimization process to focus more on the semantic differences between prompts. Extensive experiments demonstrate that the proposed Progressive3D framework generates precise 3D content for prompts with complex semantics and is general for various text-to-3D methods driven by different 3D representations.
Method
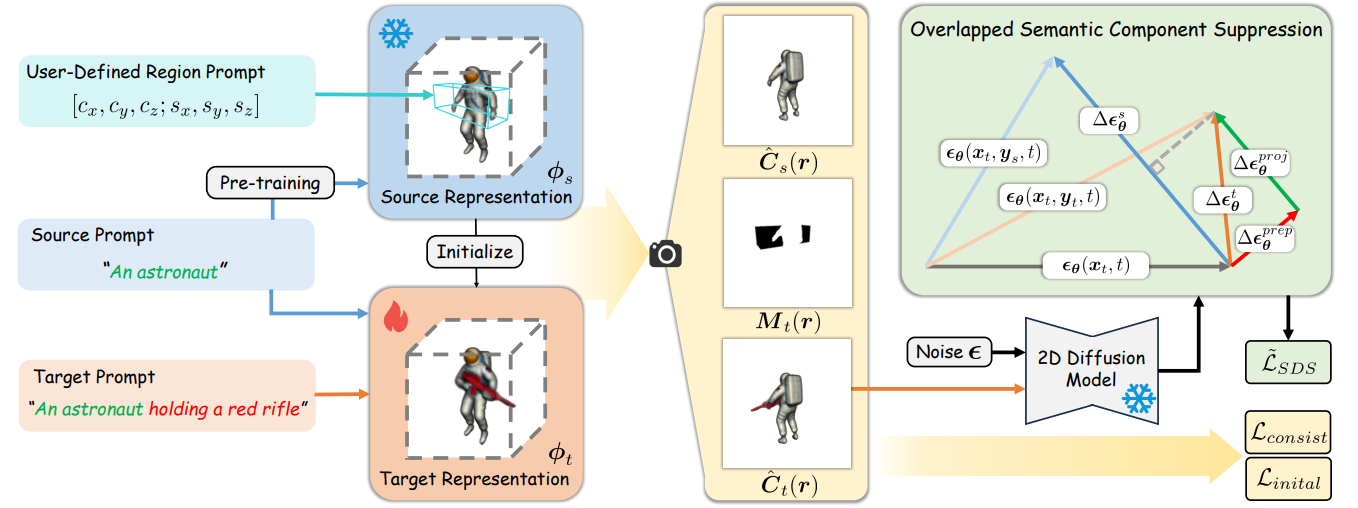
Overview of a local editing step of our proposed Progressive3D. Given a source representation supervised by source prompt, our framework aims to generate a target representation conforming to the input target prompt in 3d space defined by the region prompt. Conditioned on the 2D mask, we constrain the 3D content with region-related constraints. We further propose an Overlapped Semantic Component Suppression technique to impose the optimization focusing more on the semantic difference for precise progressive creation.
Progressively Local Editing Process
Current text-to-3D methods suffer from challenges when given prompts describing objects with different attributes. Compared to generating with existing methods, generating with Progressive3D produces 3D content consistent with given prompts.
Comparison
We provide progressive editing processes driven by different text-to-3D methods. For each sample groups, the results in upper row are generated by baseline methods and the results in bottom row are generated by Progressive3D.
BibTeX
@misc{cheng2023progressive3d,
title={Progressive3D: Progressively Local Editing for Text-to-3D Content Creation with Complex Semantic Prompts},
author={Xinhua Cheng and Tianyu Yang and Jianan Wang and Yu Li and Lei Zhang and Jian Zhang and Li Yuan},
year={2023},
eprint={2310.11784},
archivePrefix={arXiv},
primaryClass={cs.CV}
}