
Selected Publications
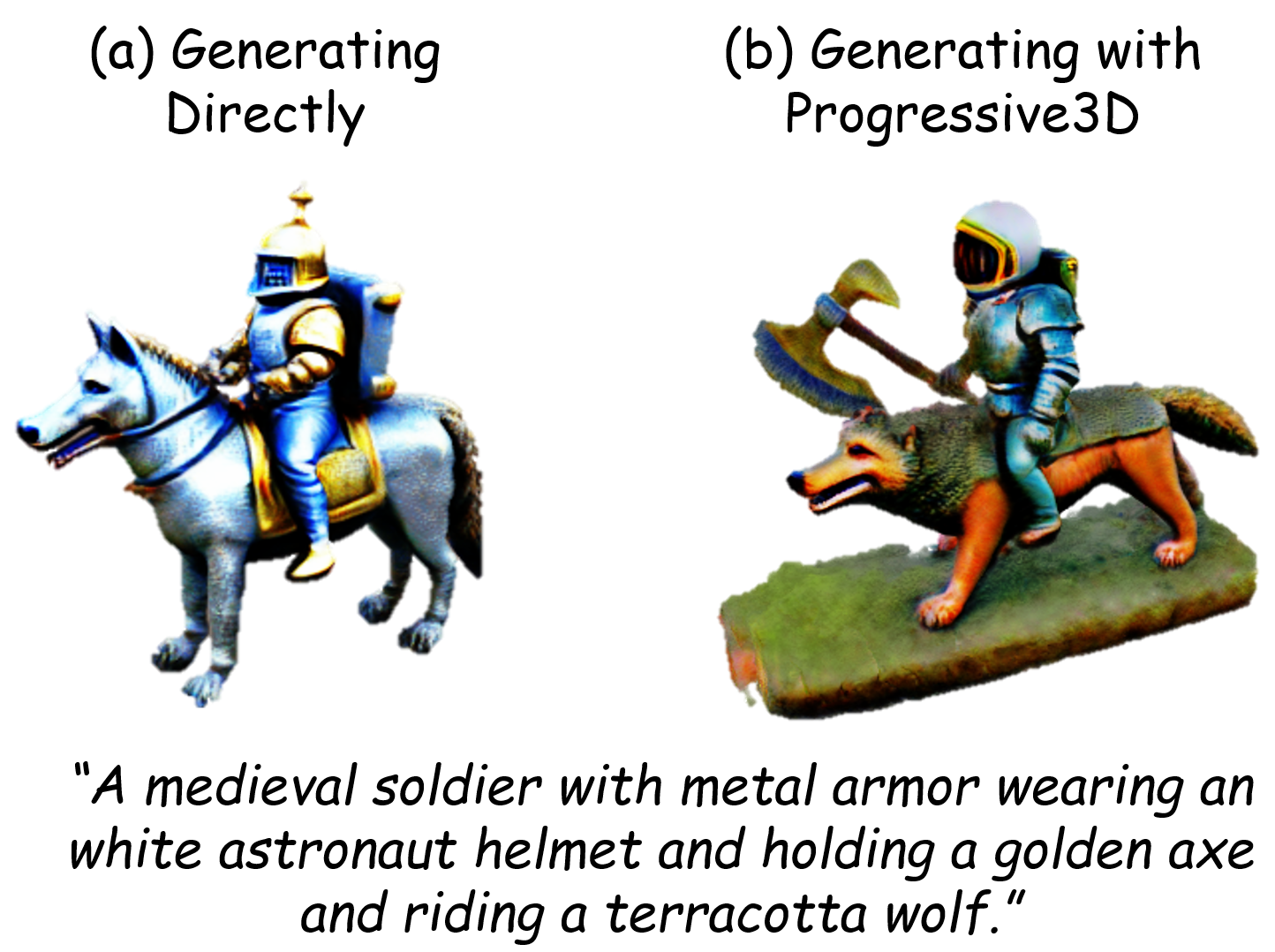
Progressive3D: Progressively Local Editing for Text-to-3D Content Creation with Complex Semantic Prompts
International Conference on Learning Representations (ICLR), 2024

We introduce progressive local editing to create precise 3D content consistent with prompts describing multiple interacted objects binding with different attributes.

Null-Space Diffusion Sampling for Zero-Shot Point Cloud Completion
International Joint Conference on Artificial Intelligence (IJCAI), 2023
We propose a zero-shot point cloud completion framework by only refining the null-space content during the reverse process of a pre-trained diffusion model.

Panoptic Compositional Feature Field for Editable Scene Rendering with Network-Inferred Labels via Metric Learning
Conference on Computer Vision and Pattern Recognition (CVPR), 2023
We introduce metric learing for leveraging 2D network-inferred labels to obtain discriminating feature fields, leading to 3D segmentation and editing results.
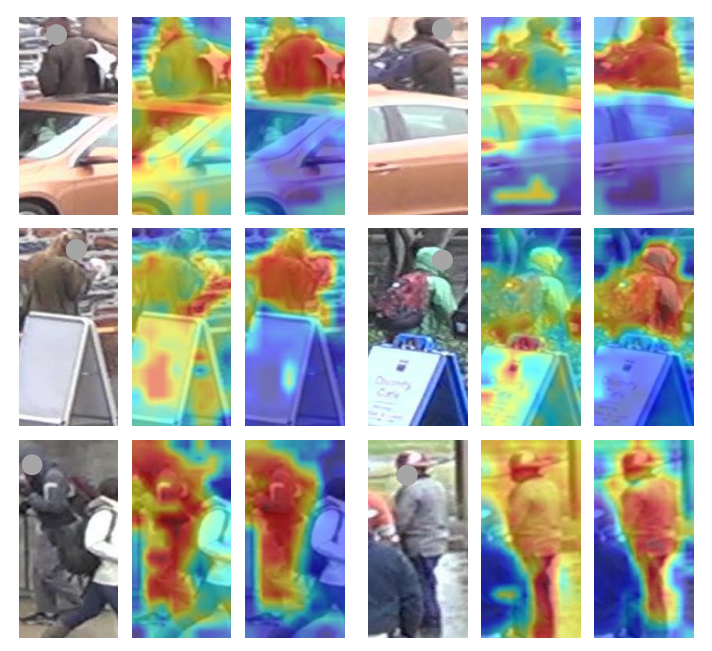
More is better: Multi-source Dynamic Parsing Attention for Occluded Person Re-identification
ACM International Conference on Multimedia (ACM MM), 2022
We introduce the multi-source knowledge ensemble in occluded re-ID to effective leverage external semantic cues learned from different domains.

A Simple Visual-Textual Baseline for Pedestrian Attribute Recognition
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2022

We model pedestrian attribute recognition as a multimodal problem and build a simple visual-textual baseline to captures the intra- and cross-modal correlations.

